This is the first in a series of posts that recap Colin’s talk at the San Francisco Meetup 6/14 and go into some detail about structuring a SproutCore application. Stay tuned for more posts in this series, and, as always, we’re listening to your feedback- let us know where you’re confused or what you want to learn more about.
Building applications that scale well is very important, but “scaling well” isn’t limited to ensuring your servers can handle the load. It is equally important to structure your application so that you can easily maintain your code and introduce new functionality without needing to rewrite significant portions. There are libraries provided by SproutCore, like the statechart library, that will help your application grow smoothly.
Let’s dive into how to structure your SproutCore application so that it’s maintainable and can grow with your project. In Part 1, I’ll be covering how to set up your application so that you will be able to add functionality later with minimal refactoring.
Introduction
We’ll be going through an application I built for the SproutCore San Francisco Meetup earlier this month. It is available on Github.
To get started, let’s generate the application using the following command:
sc-init Contact --template
As you can see, we’ve named our application Contact and we’re choosing to use the new HTML-based application structure. We’re going to be developing this SproutCore 1.6 application so that we can upgrade it to the SproutCore 2.0 stream eventually. That means using SC.TemplateView for all of our content views, and limiting our usage of other views that rely on layout.
To get set up with the repository that is on Github, clone the repository by running
git clone git://github.com/ColinCampbell/Contact.git
Now that we’ve got an application set up, let’s take a look at the pieces that SproutCore provides and how they fit together. Here’s a general overview:
-
DataStore framework to manage your data
-
SC.View/SC.TemplateView to create your UI
-
SC.ArrayController/SC.ObjectController to connect your data to your views
-
SC.Statechart to manage your application logic
Let’s start building an app and see how to write maintainable code in SproutCore.
Adding Initial DataStore Code
The first thing you’ll do when you’re developing an application is introduce some models and a store to manage the data that you’ve loaded. For this application, we’re going to provide the data for the application by using fixtures, which allows you to bootstrap your SproutCore application with data that isn’t provided from a server or API. If you’re following along with the prebuilt repository, check out the step1 branch by running
In the contact.js file, we’ve added the store object on the application’s namespace.
Contact = SC.Application.create({
store: SC.Store.create().from('Contact.FixturesDataSource')
});
This will give you access to the store from anywhere in the application code. If you check the contents of the models/ folder inside the application’s directory, you’ll see we’ve introduced the Contact.Person and Contact.Group models.
// in apps/contact/models/group.js:
Contact.Group = SC.Record.extend({
name: SC.Record.attr(String),
people: SC.Record.toMany('Contact.Person', {inverse: 'group'})
});
// in apps/contact/models/person.js
Contact.Person = SC.Record.extend(
firstName: SC.Record.attr(String, {defaultValue: "Señor"}),
fullName: function() {
var firstName = this.get('firstName'),
lastName = this.get('lastName');
return firstName + ' ' + lastName;
}.property('firstName', 'lastName').cacheable(),
group: SC.Record.toOne('Contact.Group', {inverse: 'people'}),
lastName: SC.Record.attr(String)
});
The attributes for these models allow for names, and we’ve also added a relationship so we can connect a Group to many Person records. We’ve also built some fixture data for these models, which you can see in the fixtures folder. Now that we’ve covered the beginning of the data layer for our application, let’s build out the views.
Scaffolding The View Layer
The next step in bootstrapping our application is to rough out the views that we’ll want. Check out the second step in the git repository by running
Looking at the contact.js file again, you’ll see we’ve introduced the Contact.pane object, which will serve as our main view for the application. It contains a sidebar, where we’ll list the groups and people, and an SC.ContainerView, which we’ll use to swap out views that will allow us to edit Contact.Group or Contact.Person records. Those views, which are going to be based on SC.TemplateView, are below the pane object.
Contact.pane = SC.Pane.create({
layout: {centerX: 0, centerY: 0, height: 400, width: 800},
childViews: ['sidebar', 'contentView'],
classNames: ['app'],
defaultResponder: 'Contact.statechart',
sidebar: SC.View.design({
layout: {width: 200},
childViews: ['sidebar'],
classNames: ['sidebar'],
sidebar: SC.TemplateView.design({
templateName: 'sidebar'
})
}),
contentView: SC.ContainerView.design({
layout: {left: 201},
nowShowingBinding: 'Contact.displayController.nowShowing'
})
});
Contact.groupView = SC.TemplateView.create({
classNames: ['group'],
contentBinding: 'Contact.groupController',
templateName: 'group'
});
Contact.personView = SC.TemplateView.create({
classNames: ['person'],
contentBinding: 'Contact.personController',
templateName: 'person'
});
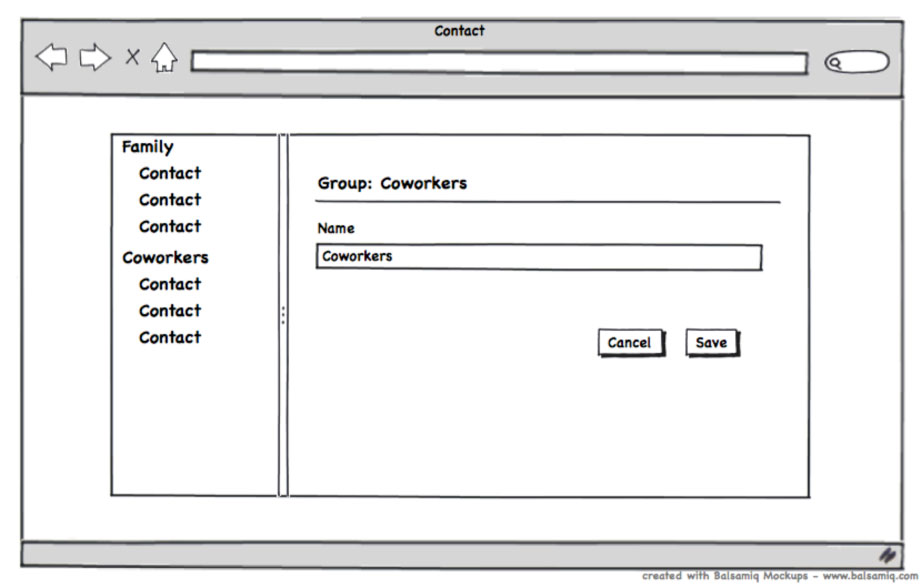
For our content views, we’re going to use SC.TemplateView. This allows you to declare your views using the Handlebars templating system. As you can see in the definition of Contact.groupView and Contact.personView, we’re providing templateName values which correspond to the name of files containing those templates. For example, in apps/contact/resources/templates/group.handlebars, we’ve defined the Handlebars template to show in the Contact.groupView view:
<h2>Group: {{content.name}}</h2>
<ul class="form">
<li>
<label for="name">Name:</label>
{{view SC.TextField name="name" valueBinding="Contact.groupController.name"}}
</li>
</ul>
<div class="buttons">
{{#view SC.Button action="cancel" classNames="button cancel"}}
Cancel
{{/view}}
{{#view SC.Button action="save" classNames="button save"}}
Save
{{/view}}
</div>
There are a few things to notice here.
First, in our header for the view, we’re binding to the content.name property. When we defined the Contact.groupView above, we bound its content property to the Contact.groupController object. This means that when this template renders, it will use the currently selected group’s name in the header, and this will automatically update when that controller’s content is changed.
We’re also using some views that SproutCore provides to easily handle rendering input fields and buttons. We’ve bound the SC.TextField for changing a name to the Contact.groupController’s name property. Now that we’ve built the initial view structure to represent the UI layer of our application, we need to build out the controllers and statechart so our application can function.
Controllers and Statecharts
If you’re following along using the Git repository, checkout the step3 branch by running
In this step, we’re going to build out our controller layer, as well as the initial structure of our statechart. Looking to the controllers/ folder, you’ll see we’ve added SC.ObjectControllers and SC.ArrayControllers to handling wiring our data for our views.
In contact.js, we’ve also added the initial statechart structure for our application:
Contact.statechart = SC.Statechart.create({
autoInitStatechart: false,
rootState: SC.State.design({
initialSubstate: 'ready',
signIn: SC.State.plugin('Contact.SignInState'),
ready: SC.State.plugin('Contact.ReadyState')
})
});
Here, we create the statechart by calling SC.Statechart.create(). We want to wait until the ready event to actually start our statechart, so we set autoInitStatechart to false.
We’re going to implement two main states, a signIn state and a ready state, but for now, we just want to enter the ready state. This state will represent the application once the user has been authenticated and the main application is shown.
You’ll notice that we’ve removed the Contact.pane.append calls from the main file, and moved them into the ReadyState, which is defined in apps/contact/states/ready.js. This means the pane will get appended when that state is entered and removed when it is exited.
Continuing On
Now that we’ve got the initial application structure completed, we can start implementing some functionality. In the next post, I’ll be showing how to load your data, display it to the user by setting the controllers’ content, and modify groups and people using the templates we’ve already defined.